التنبؤ بدرجات الحرارة باستخدام الانحدار الخطي: مشروع تعليمي
التنبؤ بدرجات الحرارة باستخدام الانحدار الخطي: مشروع تعليمي للمبتدئين في تعلم الآلة
تعلّم الآلة (Machine
Learning) هو مجال رئيسي ضمن الذكاء الاصطناعي
(AI) يسمح للأنظمة بالتعلم
التلقائي والتحسين المستمر من خلال التجربة، دون الحاجة إلى برمجة صريحة.
يعتمد على تطوير الخوارزميات التي تستطيع الوصول إلى البيانات،
تحديد الأنماط، واتخاذ القرارات بفعالية مع تدخل بشري محدود. يُستخدم تعلّم
الآلة في العديد من التطبيقات، بما في ذلك التنبؤ بدرجات الحرارة،
التمويل، الرعاية الصحية، السيارات ذاتية
القيادة، ومعالجة اللغة الطبيعية.
في هذا المشروع، سنستخدم الانحدار الخطي لتطبيق تنبؤ
درجات الحرارة باستخدام Python وGoogle Colab، وهو مشروع مثالي للمبتدئين الذين يرغبون في تعلم أساسيات تحليل
البيانات وتعلّم الآلة.
أنواع
تعلم الآلة
التعلم
الموجّه
(Supervised Learning):
في التعلم
الموجّه، يتم تدريب النموذج على بيانات محددة مسبقًا معروفة النتائج (البيانات
المعلّمة). يتعلم النموذج ربط المدخلات بالمخرجات المرغوبة عن طريق تقليل الخطأ
بين التوقعات والقيم الفعلية. الأمثلة تشمل مهام الانحدار والتصنيف.
الانحدار (Regression): يتنبأ
بالقيم المستمرة (مثل التنبؤ بأسعار المنازل).
التصنيف (Classification): يتنبأ بالمخرجات الفئوية (مثل رسائل البريد
العشوائي أو غير العشوائي).
التعلم
غير الموجّه (Unsupervised
Learning): في التعلم غير
الموجّه، يعمل النموذج مع بيانات غير معلمة. الهدف هو العثور على أنماط أو علاقات
خفية في البيانات. يتم استخدامه عادةً في التجميع (clustering) والربط.
التجميع (Clustering): تجميع نقاط البيانات في مجموعات (مثل تقسيم
العملاء).
تقليل
الأبعاد
(Dimensionality Reduction):
تقليل عدد
المتغيرات مع الحفاظ على المعلومات الهامة (مثل التحليل بالمكونات الرئيسية).
التعلم
المعزز
(Reinforcement Learning):
يتضمن التعلم
المعزز تدريب وكيل لاتخاذ القرارات من خلال مكافأة أو معاقبة أفعاله. يتفاعل
الوكيل مع البيئة ويتعلم تحقيق هدف عن طريق تعظيم المكافآت المتراكمة.
الانحدار
الخطي
(Linear Regression)
الانحدار
الخطي هو خوارزمية أساسية في التعلم الموجه تُستخدم للتنبؤ بمتغير مستهدف مستمر
بناءً على واحد أو أكثر من الميزات المدخلة. يفترض النموذج وجود علاقة خطية بين
المتغيرات المستقلة (المدخلات) والمتغير المستهدف (المخرجات).
معادلة
النموذج الخطي البسيط هي Y=β0+β1X1+ϵ
حيث:
Y
هو المتغير
المستهدف (التنبؤ),
β0
هو ثابت
المعادلة
(y-intercept),
β1
هو معامل الميزة
X1,
ϵ يمثل خطأ التنبؤ.
مقاييس
تقييم النموذج
(Model Evaluation Metrics)
تعتبر
مقاييس تقييم النموذج أساسية لتقييم أداء نماذج تعلم الآلة. بالنسبة لنماذج
الانحدار مثل الانحدار الخطي، تشمل المقاييس الشائعة ما يلي:
-
متوسط الخطأ المطلق (Mean Absolute Error - MAE): يقيس MAE متوسط الفروق
المطلقة بين القيم المتوقعة والقيم الفعلية. يقدم تفسيرًا مباشرًا لمتوسط الخطأ في
توقعات النموذج.
-
مربع R
(R-squared): يمثل مربع R النسبة المئوية للتباين في المتغير المستهدف الذي
يتم التنبؤ به من المتغيرات المستقلة. تتراوح قيمته بين 0 و 1، حيث تشير القيمة
الأقرب إلى 1 إلى ملاءمة أفضل للنموذج.
المشروع: التنبؤ بدرجة الحرارة لليوم التالي باستخدام الانحدار الخطي
في
هذا المشروع، نهدف إلى التنبؤ بدرجة الحرارة لليوم التالي باستخدام بيانات الطقس
التاريخية. يحتوي هذا البيانات على العديد من الميزات، مثل درجة الحرارة، الرطوبة،
سرعة الرياح، الضغط الجوي، وغيرها. هدفنا هو بناء نموذج انحدار خطي للتنبؤ بدرجة
الحرارة لليوم التالي بناءً على هذه الميزات.
الخطوات
الرئيسية:
1-تحضير البيانات:
o
استيراد البيانات.
o
تحويل عمود "التاريخ" إلى تنسيق مناسب.
o
استخراج الميزات ذات الصلة مثل السنة، الشهر،
اليوم، واليوم من الأسبوع.
2-اختيار الميزات:
o
اختيار الميزات الهامة التي من المحتمل أن تؤثر
على توقعات درجة الحرارة (مثل الرطوبة، سرعة الرياح، إلخ).
3-تقسيم البيانات إلى تدريب واختبار:
o
تقسيم البيانات إلى مجموعتي تدريب واختبار لتقييم
أداء النموذج.
4-تدريب النموذج:
o
تدريب نموذج انحدار خطي على مجموعة التدريب لتعلم
العلاقة بين الميزات والمتغير المستهدف (درجة الحرارة).
5-تقييم النموذج:
o
تقييم النموذج باستخدام MAE و R² لتحديد أدائه.
استخدام Google Colab لتعلم الآلة
Google
Colab هو منصة سحابية
مجانية توفر بيئة قوية لكتابة وتنفيذ الأكواد بلغة Python. تُستخدم
بشكل واسع في مشاريع تعلم الآلة نظرًا لسهولة استخدامها والدعم المدمج للمكتبات
الشهيرة مثل
TensorFlow و PyTorch و
Scikit-learn. تتمثل الفوائد
الرئيسية لاستخدام
Google Colab في:
الوصول
المجاني إلى وحدات معالجة الرسومات
(GPUs): مما يسمح بتدريب
النماذج بشكل أسرع، خاصةً لمهام التعلم العميق.
لا
حاجة للتثبيت: يعمل Google Colab في السحابة، لذلك لا توجد حاجة لتثبيت أي برامج.
يمكنك استيراد بياناتك بسهولة وبدء البرمجة.
التعاون: يمكن بسهولة مشاركة دفاتر Colab، ويمكن لأكثر من شخص العمل على نفس الدفتر في الوقت نفسه.
الخطوة
1: فهم مجموعة البيانات
تحتوي
مجموعة البيانات الخاصة بك على الأعمدة التالية:
1-
Date )التاريخ): تاريخ
ووقت تسجيل الطقس.
2-
Summary )الملخص): ملخص
موجز لحالة الطقس.
3-
Precip Type(نوع الهطول): نوع الهطول (المطر/الثلج).
4-
Temperature (C)
)درجة الحرارة):
درجة الحرارة المسجلة الفعلية.
5-
Apparent
Temperature (C) )درجة
الحرارة المحسوسة): درجة الحرارة التي يشعر بها الشخص.
6-
Humidity )الرطوبة): مستوى
الرطوبة.
7-
Wind Speed
(km/h) )سرعة الرياح):
سرعة الرياح بالكيلومتر في الساعة.
8-
Wind Bearing
(degrees) (اتجاه
الرياح): اتجاه الرياح بالدرجات.
9-
Visibility (km)
(الرؤية):
مدى الرؤية بالكيلومترات.
10-
Cloud Cover (تغطية السحب): نسبة تغطية السحب.
11-
Pressure
(millibars) (الضغط
الجوي): الضغط الجوي بوحدة ميليبار.
12-
Daily Summary (الملخص اليومي): وصف موجز لحالة الطقس
اليومية.
الهدف من التنبؤ سيكون درجة الحرارة لليوم التالي
Step 2: Load and Explore the Data
Let's first load the data using pandas and explore it.**
import pandas as pd# Load datasetdf = pd.read_csv('weather_data.csv') # Assuming CSV format# Preview the datadf.head()
Step 3: Data Preprocessing
3.1 Handling Missing Data Check for missing values and decide how to handle them. For simplicity, we'll fill missing values with the column's median or drop rows if a large percentage of data is missing.**
# Check for missing valuesdf.isnull().sum()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 96453 entries, 0 to 96452 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Formatted Date 96453 non-null object 1 Summary 96453 non-null object 2 Precip Type 95936 non-null object 3 Temperature (C) 96453 non-null float64 4 Apparent Temperature (C) 96453 non-null float64 5 Humidity 96453 non-null float64 6 Wind Speed (km/h) 96453 non-null float64 7 Wind Bearing (degrees) 96453 non-null float64 8 Visibility (km) 96453 non-null float64 9 Loud Cover 96453 non-null float64 10 Pressure (millibars) 96453 non-null float64 11 Daily Summary 96453 non-null object dtypes: float64(8), object(4) memory usage: 8.8+ MB
3.2 Feature Engineering
We can add useful features like Month, Day, Year, and Day of the week from the date to help improve predictions.italicized text
# Convert the 'Formatted Date' column to datetime formatdf['Formatted Date'] = pd.to_datetime(df['Formatted Date'], errors='coerce')# Verify the conversiondf.info()output0 Formatted Date 56469 non-null datetime64[ns, UTC+02:00]
df['Year'] = df['Formatted Date'].dt.yeardf['Month'] = df['Formatted Date'].dt.monthdf['Day'] = df['Formatted Date'].dt.daydf['DayOfWeek'] = df['Formatted Date'].dt.dayofweek
3.3 Feature Selection
We will drop columns that may not directly help predict temperature, such as text-based fields (Summary, Precip Type, Daily Summary).
# Drop columns not needed for the prediction# سوف يتم سحب الاعمدة التي لانحتاجها وليس لها تأثيرdf.drop(columns=['Formatted Date', 'Summary', 'Precip Type', 'Daily Summary'], inplace=True)
3.4 Setting up Labels (Next Day’s Temperature)
We will shift the Temperature (C) column by 1 day to predict the next day's temperature.
# Shift temperature to create the target column (next day's temperature)df['Next_Day_Temperature'] = df['Temperature (C)'].shift(-1)# Drop the last row since it won't have a targetdf.dropna(inplace=True)
Step 4: Split Data into Training and Test Sets
We split the data into training and test sets to evaluate our model's performance.
from sklearn.model_selection import train_test_split# Define features (X) and target (y)#(y درجة الحرارة) تعريف البيانات المدخلة والهدف الي يمثلX = df.drop(columns=['Next_Day_Temperature'])y = df['Next_Day_Temperature']# Split the data (80% training, 20% testing)# تقسيم البيانات بنسبه 20بالمائة للاختبار وغالبا النسبه تتراواح بين 20 الى 25X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Step 5: Model Selection and Training
We will use Linear Regression for simplicity.
from sklearn.linear_model import LinearRegression# Initialize and train the model#اختيار النموذج وتدريبهmodel = LinearRegression()model.fit(X_train, y_train)
from sklearn.metrics import mean_absolute_error, r2_score# Predict on the test sety_pred = model.predict(X_test)
Step 6: Model Evaluation
Evaluate the model on the test data using Mean Absolute Error (MAE) and R-squared (R²).
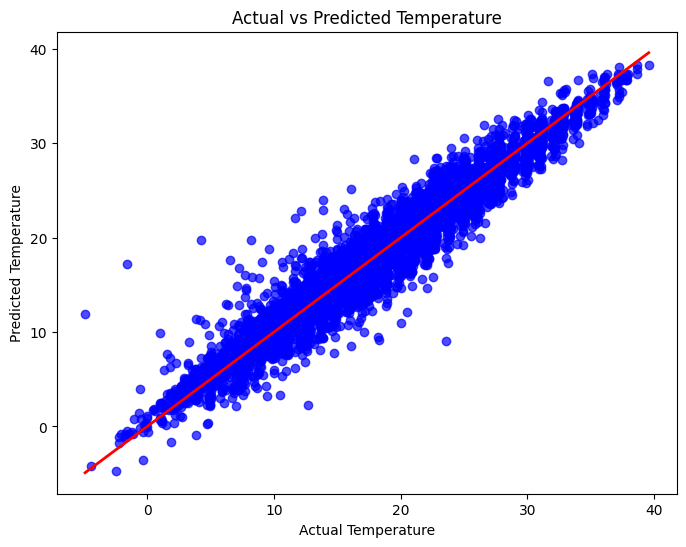
# Calculate MAE and R²#تقييم النموذجmae = mean_absolute_error(y_test, y_pred)r2 = r2_score(y_test, y_pred)print(f'Mean Absolute Error: {mae}')print(f'R-squared: {r2}')Mean Absolute Error: 1.1970096407635922 R-squared: 0.9455129195250398
تفسير النتائج:
متوسط الخطأ المطلق (MAE): 1.197
يمثل متوسط الخطأ المطلق الفرق المتوسط بين القيم المتوقعة والقيم الفعلية. في هذه الحالة، يبلغ متوسط الخطأ حوالي 1.197 درجة مئوية، مما يشير إلى أن توقعات النموذج لدرجة الحرارة تخطئ في المتوسط بنحو 1.2 درجة مئوية.
معامل التحديد (R²): 0.945
يوضح معامل التحديد مدى جودة ملاءمة النموذج للبيانات. النتيجة 0.945 تعني أن النموذج يفسر 94.5% من التباين في بيانات درجة الحرارة الفعلية، مما يشير إلى أن النموذج يلائم البيانات بشكل ممتاز.
# Plot the predicted vs actual values# من رسم النموذج يوضح التقاط النموذج للبياناتplt.figure(figsize=(8,6))plt.scatter(y_test, y_pred, alpha=0.7, color='blue')plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='red', linewidth=2)plt.xlabel('Actual Temperature')plt.ylabel('Predicted Temperature')plt.title('Actual vs Predicted Temperature')plt.show()
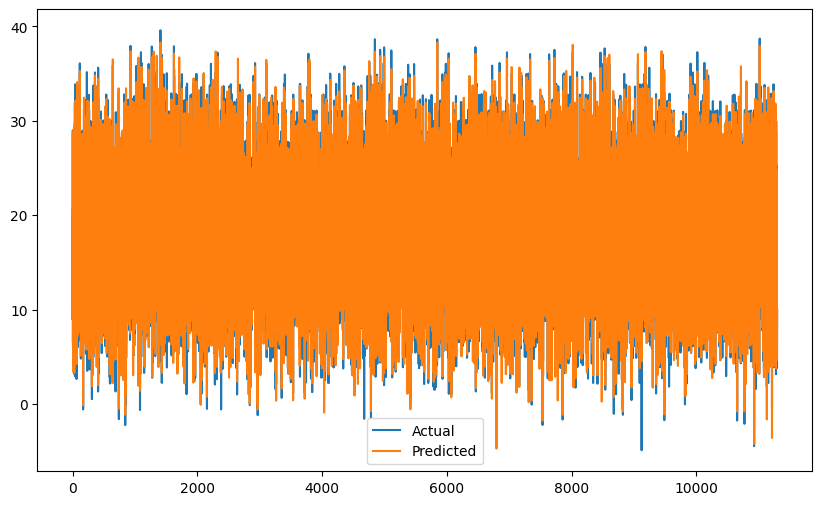
# Plot Actual vs Predictedplt.figure(figsize=(10, 6))plt.plot(y_test.values, label='Actual')plt.plot(y_pred, label='Predicted')plt.legend()plt.show()
import joblib# Save the model to a file#حفظالنموذج اختياري في حال كان نتيجة المودل جيدةjoblib.dump(model, 'temperature_predictor.pkl')
